
のスキャンダル ケンブリッジアナリスト それはまだ終わっていない。 一度 マーク·ザッカーバーグ 米国議会と上院を通過した後、Facebookの責任者が間違ったことをしただけで、申し訳なかったと述べたことを確認した後、私たちはほろ苦い気持ちになりました。 彼は決して述べていません 私は将来そのような問題を回避するつもりでした。
Facebookが私たちについて持っているデータの量は とてもすごい怖い、したがって、ブラックミラーシリーズの第2016シーズンの最初のエピソードとの比較は避けられません。 ケンブリッジアナリティカ社が昨年のXNUMX年のアメリカ大統領選挙で投票する意図を修正するために虚偽のニュースを作成することを可能にしたこのスキャンダルの後、Facebookが私たちについて保存しているデータの量にまだ気付いていない場合は、お見せしますなので Facebookのすべてのデータのコピーをダウンロードします。
Facebookは私についてどのくらい知っていますか?
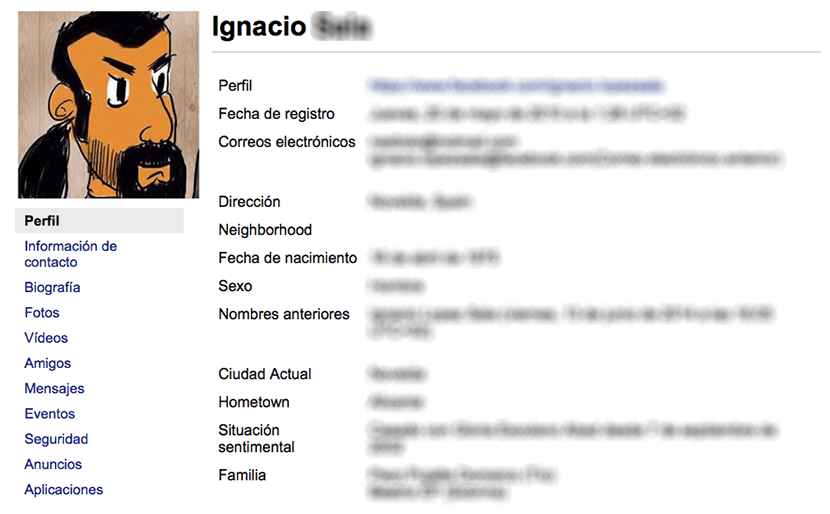
あなたにアイデアを与えるために、私たちのデータのコピーをダウンロードしてどの程度まで見ることがどれほど重要であるかを知るために Facebookは私たちを出産した母親よりも私たちをほとんどよく知っていますFacebookが私たちについて持っているいくつかの種類の情報は次のとおりです。
- スマートフォンの電話帳にあるすべての連絡先
- クリックした広告。
- すべてのチャット会話の完全な履歴。
- アクセスしたWebページ。
- あなたが住んでいる都市
- あなたが参加した、参加した、または招待されたイベント。
- 顔認識データ。
- あなたの家族のメンバーは何ですか。
- あなたの親友は何ですか。
- Facebookへの接続に使用した、または使用しているすべてのIPアドレス、および日時。
- ソーシャルネットワークを参照または作成したすべての場所。
- アカウントに投稿または書き込んだすべてのメモ。
- 電話番号と住所。
- 写真のメタデータを介してアクセスする場所。
- あなたに関する他の人の投稿。
- Facebookに参加した日付。
- 友達リストから削除した友達。
- Facebookで行ったすべての検索。
- 共有したすべてのコンテンツ。
- あなたの現在の仕事とあなたが以前働いた場所
- 宗教的信念
- 政治的イデオロギー。
これはXNUMXつだけ Facebookが私たちについて持っている情報の小さなサンプル。 プロフィールができるだけリアルになるように手動で追加したものもありますが、訪問した場所など、画像のGPS座標から取得したものもあれば、政治的イデオロギーや宗教的信念(手動で指定していません)は、私たちがフォローしているWebページ、私たちが作成し、会話でコメントしている出版物から取得されています...ご覧のとおり、Facebookはプラットフォームに書き込んだデータを実質的に分析します。
Cambridge Analyticaがアクセスする際の問題は、特定の調査を実施したすべての人々から情報を入手したことではなく、このデータを通じて、 それを作ったすべてのユーザーのすべての友人や親戚にアクセスできましたしたがって、世界中で影響を受けるユーザーの現在の数は、最初の50万人から 現在の87万。
Facebookのすべてのデータのコピーをダウンロードする
まず最初に、Facebook Webサイトにアクセスし、ユーザー名とパスワードを入力する必要があります。 健康的な習慣 壁を訪れたばかりのたびにログアウトし、Facebookがどこに行くのか、何をするのか、どこに行くのかを知らないようにします。
ソーシャルネットワークを離れた後、どのWebページにアクセスしたかをFacebookが常に認識しないようにしたい場合は、 Firefoxは私たちに拡張機能を提供します それは、私たちのチームの閲覧履歴にいつでもアクセスできる場合にFacebookを閲覧できるようにするための専用タブを開くことを担当します。このタブは、Firefoxから独立したブラウザであるかのように機能します。 強くお勧めします
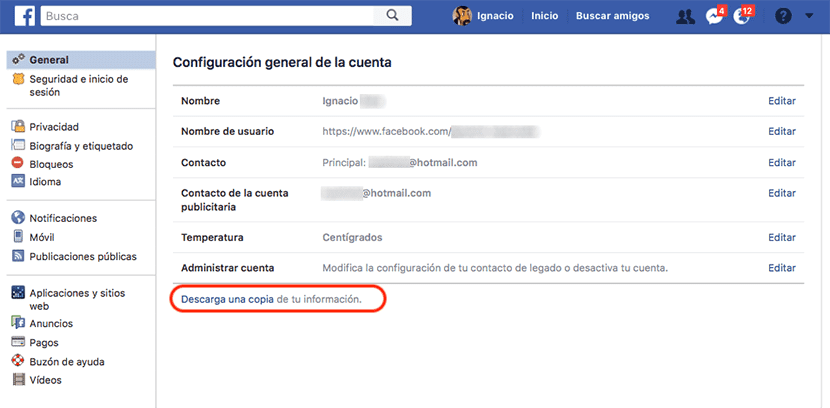
Facebookが私たちについて保存しているすべての情報のコピーをダウンロードしたい場合は、 アカウントを作成してから、まず最初に行かなければなりません Facebookアカウントの一般設定。 [一般]セクションの右側で、[情報のコピーをダウンロードする]オプションを探します。これは最後にあります。

次に、[情報のダウンロード]セクションにアクセスします。このセクションでは、Facebookで共有した個人情報のコピーをダウンロードすることを通知します。これには、すべての写真、ビデオ、チャットメッセージ、出版物が含まれます。ソーシャルネットワークが私たちについて所有しているその他のデータ。 プロセスを開始するには [ファイルを作成]をクリックします。
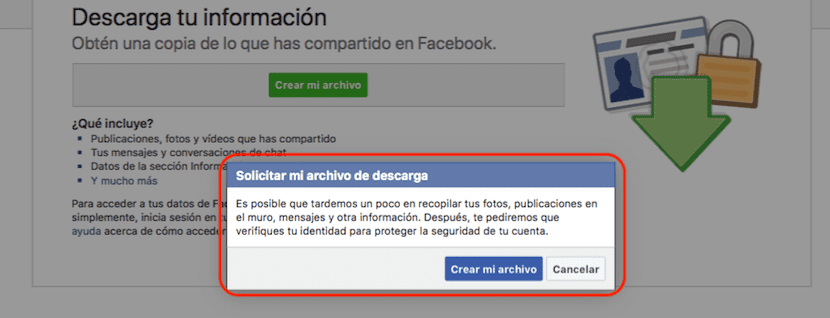
Facebookでの活動によっては、プロセスの作成に多少時間がかかる可能性が高いため、ソーシャルネットワークは次のことを通知するメッセージを表示します。 ソーシャルネットワーク上で公開または共有したすべての情報を収集するには、しばらく時間がかかります。 さらに、セキュリティを保護するために、パスワードの再入力も求められます。
この措置は、Facebook Webサイトにアクセスするたびにログアウトしないと、ユーザーのアカウントに直接アクセスするため、友人や親戚のコンピューターを使用してプロセスを実行している場合、その履歴をダウンロードできないようにするために正当化されます。 。 クリック ファイルを作成します。
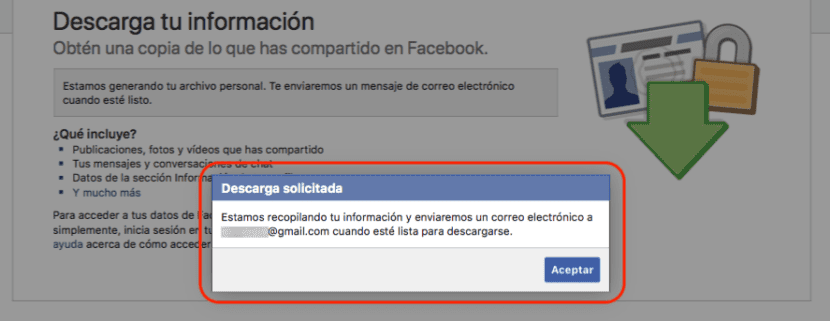
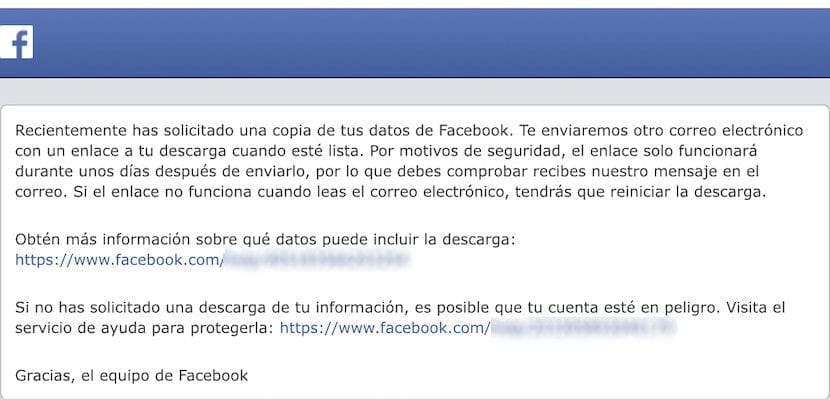
次に、次のことを通知する新しいメッセージが表示されます 彼らは私たちの情報を収集しています ダウンロードの準備ができたらメールでお知らせします。 このメールでは、プロセスの開始が通知されますが、要求したのが私たちでない場合に備えて、プロセスを回避することもできます。
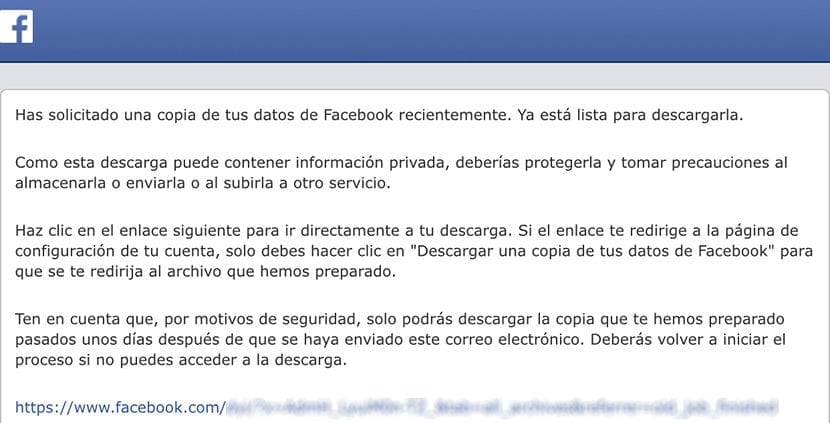
このプロセスには何分もかかりません。 ファイルが作成されると、すべての情報をダウンロードするためのリンクが記載されたメールが届きます。
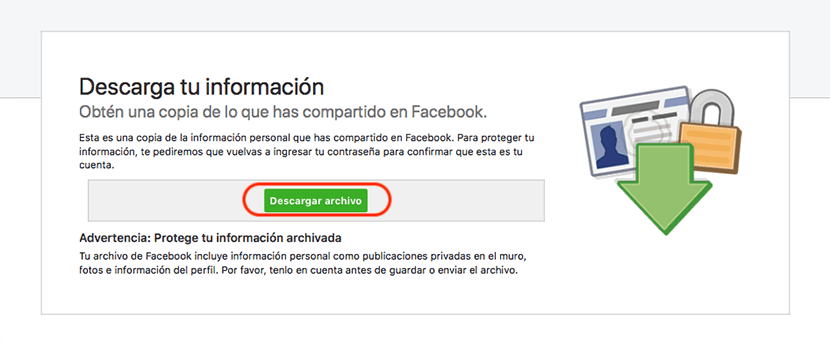
次に、をクリックする必要があります ダウンロードファイル、 Facebookがそのプラットフォームに何年にもわたって保存したすべてのコンテンツのダウンロードを開始します。

しかし前に アカウントのパスワードの入力を再度求められます私たちが正当な所有者であることを確認するため。 入力すると、zip形式の圧縮ファイルのダウンロードが開始されます。
Facebookからダウンロードした情報を含むファイルには何が含まれていますか?

私たちのチームでは 名前の付いたファイルがダウンロードされます facebook-ユーザー名。 解凍すると、一般的なindex.htmlファイルとディレクトリ(html、メッセージ、写真、ビデオ)が表示されます。 各ディレクトリにはコンテンツが個別に保存されます。オリジナルを失った場合にソーシャルネットワークにアップロードしたすべてのコンテンツのコピーを作成する場合に最適です。 問題は、ビデオと写真の両方の解像度が元の解像度からかけ離れていることですが、少なくとも何も保持できないよりはましです。
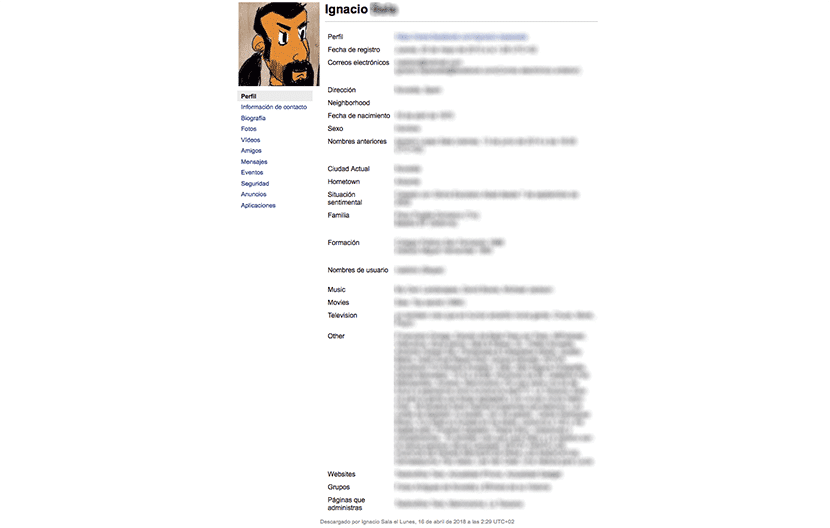
保存されたコンテンツに構造化された方法でアクセスできるようにするには、 index.htmlファイルを開きます。 ファイルをXNUMX回クリックするだけで、チームのデフォルトのブラウザがファイルを開くことができます。 左側の列では、プロフィール、連絡先情報、経歴、写真、ビデオ、友達、メッセージ、イベント、セキュリティ、お知らせ、アプリケーションに関する情報にアクセスできます。
Facebookが私たちについて持っているすべての情報は、ソーシャルネットワークによってその広告プラットフォームを導くために使用されます。このように、Facebookサービスを雇って広告を出すクライアントは 特定のニッチな人々にのみ広告を表示する たとえば、子供と猫(犬ではない)がいて、結婚していて、旅行が好きで、40〜50歳で、5〜10歳の息子がいて、アクション映画も好きな女性(それをより難しくするためのロマンチックなもの)とサッカー。