
的丑闻 剑桥分析公司 还远远没有结束。 一度 马克·扎克伯格 在经历了美国国会和参议院的审议之后,我们在检查Facebook负责人如何只说自己做错了和对不起后,感到苦乐参半。 他从未说过 我打算将来避免此类问题。
Facebook关于我们的数据量为 太棒了,太可怕了,因此与《黑镜》系列第三季的第一集进行比较是不可避免的。 如果在此丑闻过后(这使Cambridge Analytica公司制造了虚假新闻,以修改上一次2016年美国大选的投票意图),而您仍然不知道Facebook存储的关于我们的数据量,那么我们将向您显示作为 下载我们所有Facebook数据的副本。
Facebook对我了解多少?
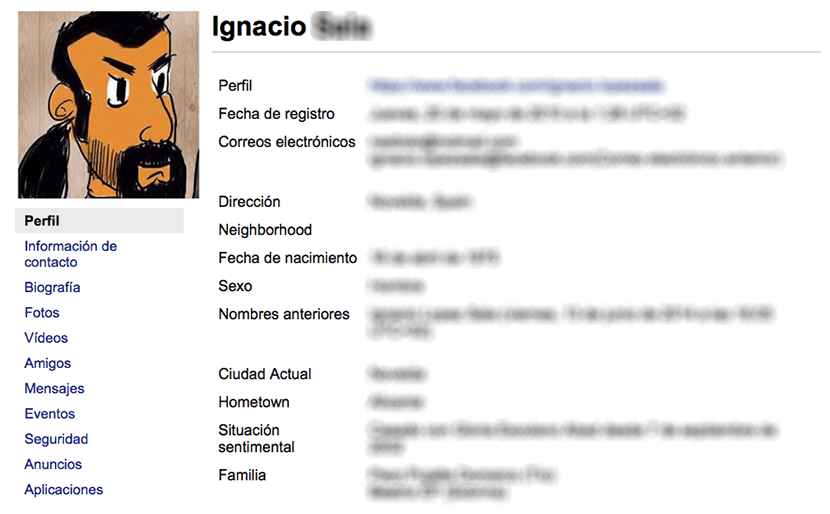
为了给您一个想法,下载我们的数据副本以查看在多大程度上有多重要 Facebook几乎比生我们的母亲更了解我们这是Facebook关于我们的某些类型的信息:
- 我们智能手机电话簿中的所有联系人
- 您点击的广告。
- 我们所有聊天对话的完整历史记录。
- 您访问过的网页。
- 您居住的城市
- 您参加,参与或受邀参加的活动。
- 面部识别数据。
- 你的家人是什么?
- 你最好的朋友是什么?
- 您已使用或正在用于连接到Facebook的所有IP地址,以及时间和日期。
- 您咨询或撰写过社交网络的所有位置。
- 您发布或写入帐户的所有笔记。
- 电话号码和实际地址。
- 您通过照片的元数据访问的地方。
- 其他人关于您的信息。
- 您加入Facebook的日期。
- 您从朋友列表中删除的朋友。
- 您在Facebook上进行的所有搜索。
- 您共享的所有内容。
- 您当前的工作以及以前的工作地点
- 宗教信仰
- 政治意识形态。
这只是一个 Facebook关于我们的信息的一小部分。 我们已经手动添加了其中一些内容,以使我们的个人资料尽可能真实,但是其他图像(例如,我们参观过的地方)则是通过图像的GPS坐标获得的,而政治思想和宗教信仰(如果有的话)未手动指定它们)已通过我们关注的网页,我们制作的出版物以及我们在对话中进行评论的方式获得了...正如我们所看到的,Facebook实际上会分析我们在其平台上编写的任何数据。
Cambridge Analytica的访问问题不在于它从进行过特定调查的所有人那里获得了信息,而是通过这些数据, 可以访问所有创建它的用户的所有朋友和亲戚,因此,目前全球范围内受影响的用户数量已从最初的50万增加到了 目前的87万。
下载我们所有Facebook数据的副本
首先,如果我们已经使用了Facebook网站,则必须访问Facebook网站并输入我们的用户名和密码。 健康的习惯 每次访问我们的围墙时都要注销,以防止Facebook知道我们要去哪里,我们正在做什么和要去哪里。
如果您想阻止Facebook在离开社交网络后始终知道您访问的网页, Firefox为我们提供了扩展 如果您始终可以访问我们团队的浏览历史记录,则该页面将负责打开一个专有选项卡以浏览Facebook,该选项卡的工作方式就像是独立于Firefox的浏览器一样。 强烈推荐。
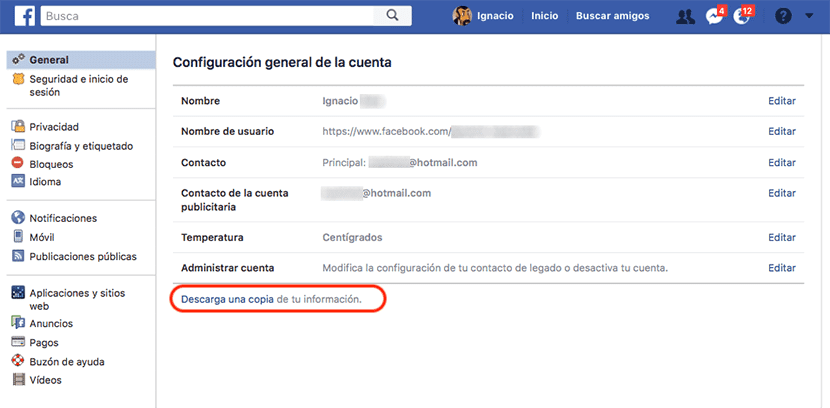
如果我们要下载Facebook存储的有关我们的所有信息的副本, 因为我们创建了一个帐户,首先我们必须去 Facebook帐户的常规设置。 在“常规”部分的右侧,我们找到位于最后的选项“下载您的信息副本”。

接下来,我们访问“下载您的信息”部分,Facebook通知我们,我们将继续下载我们在Facebook上共享的个人信息的副本,其中包括我们的所有照片,视频,聊天消息,出版物以及社交网络拥有的关于我们的其他数据。 开始这个过程 单击创建我的文件。
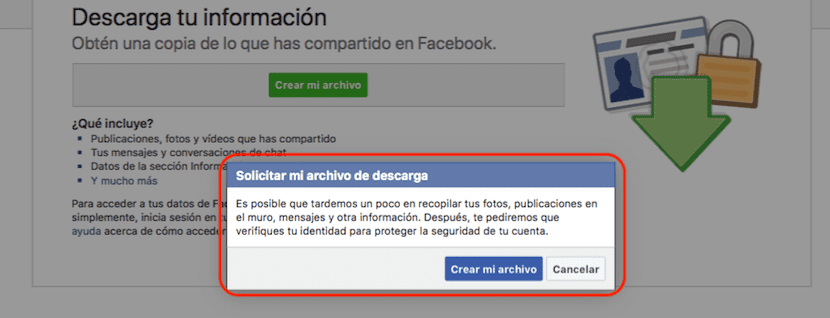
根据我们在Facebook上的活动,该过程可能或多或少地需要创建,因此社交网络将向我们显示一条消息,通知我们: 收集我们在社交网络上发布或共享的所有信息将需要一些时间。 此外,它还会要求我们重新输入密码以保护我们的安全。
此措施是合理的,因此,如果我们使用他们的计算机来执行此过程,则我们无法下载朋友或亲戚的历史记录,因为如果我们每次访问Facebook网站时都不注销,那么我们将直接访问用户的帐户。 点击 创建我的文件。
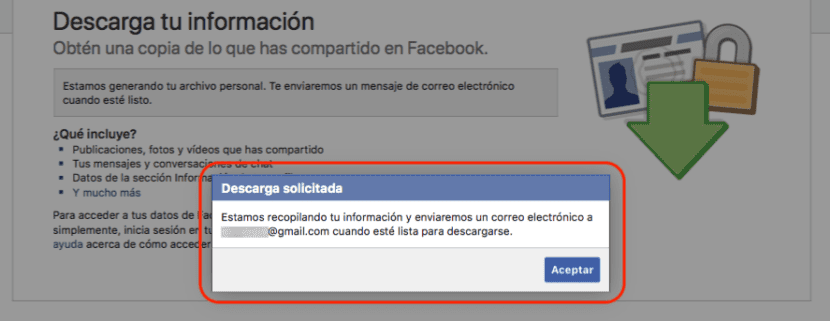
接下来,它将向我们显示一条新消息,其中告知我们 他们正在收集我们的信息 并在准备好下载时会给我们发送电子邮件。 在此电子邮件中,我们被告知了该过程的开始,但是,如果我们不是请求它的人,它也使我们可以避免它。
此过程不需要几分钟。 创建文件后,我们将收到一封电子邮件,其中包含下载所有信息的链接。
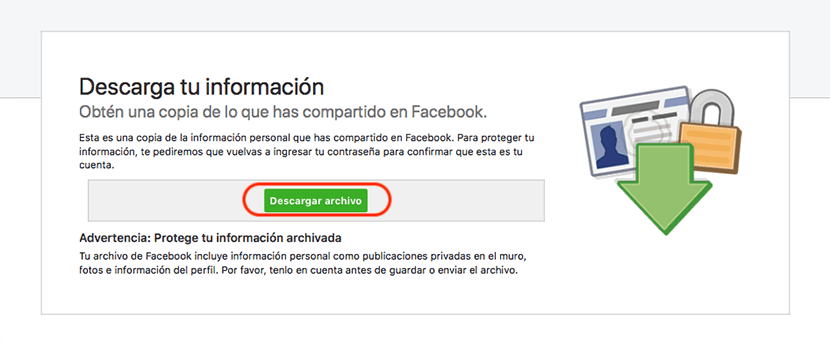
接下来,我们必须点击 下载文件, 开始下载Facebook多年来在其平台上存储的所有内容。

但是之前 它将再次要求我们提供帐户密码确认我们是合法的所有者。 输入后,将开始下载zip格式的压缩文件。
我们从Facebook下载的带有我们信息的文件包含什么?

在我们的团队中 具有该名称的文件将被下载 facebook-用户名。 通过解压缩,我们可以看到一个常规的index.html文件以及以下目录:html,消息,照片和视频。 每个目录都独立存储内容,如果丢失原始文件,我们希望复制已上传到社交网络的所有内容的副本,则是理想选择。 问题在于视频和照片的分辨率都远非原始分辨率,但至少比不保存任何东西要好。
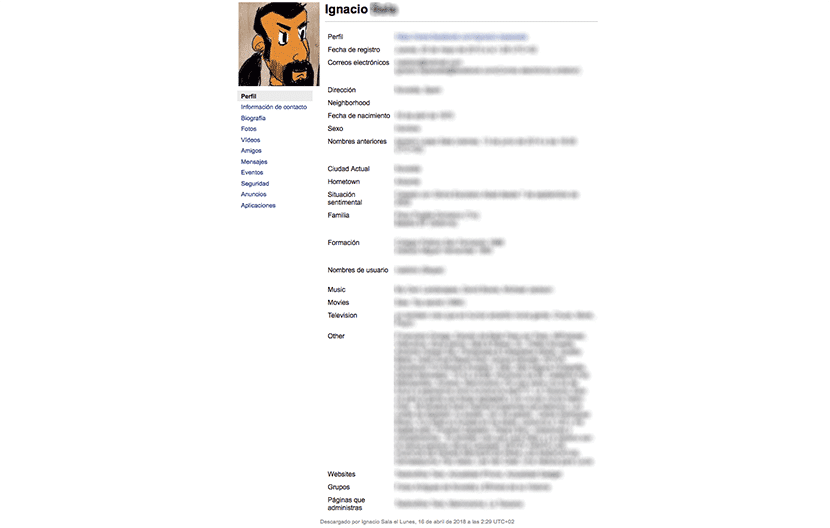
为了以结构化方式访问存储的内容,我们必须 打开index.html文件。 我们只需要单击该文件两次,以便我们团队的默认浏览器负责打开该文件。 在左栏中,我们将访问有关我们的个人资料,联系信息,传记,照片,视频,朋友,消息,事件,安全性,公告和应用程序的信息。
社交网络使用Facebook拥有的关于我们的所有信息来指导其广告平台,这样,雇用Facebook服务进行广告的客户就可以 仅在特定人群中展示您的广告 例如,有孩子和猫(而不是狗),已婚,喜欢旅行,年龄在40至50岁之间,有儿子在5至10岁之间并且还喜欢动作片的女性(不是浪漫的情节,让生活变得更加艰难)和足球。